Credit scoring algorithms are the unsung heroes of the financial world. They determine your eligibility for loans, credit cards, and even insurance policies. This exploration delves into the intricate workings of these algorithms, from their historical roots to their future applications. We’ll uncover the different types of credit scoring models, the data sources they rely on, and the ethical considerations that accompany their use.
Understanding credit scoring models is crucial for anyone interacting with financial institutions. From comprehending the factors that influence your credit score to recognizing potential biases within the systems, this overview provides a comprehensive understanding of the process.
Introduction to Credit Scoring Algorithms
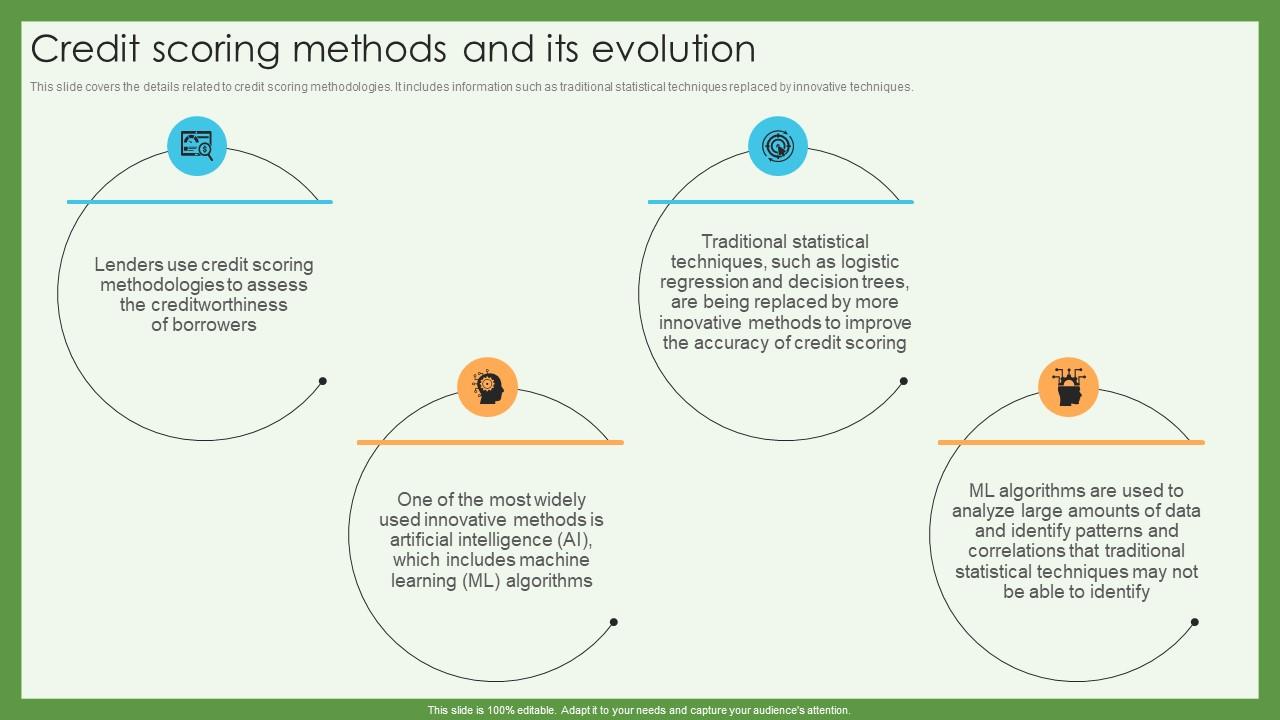
Credit scoring algorithms are sophisticated mathematical models used to assess an individual’s creditworthiness. These algorithms analyze various factors related to a person’s financial history to estimate the likelihood of them repaying a loan or credit card debt. This process allows lenders to make informed decisions about extending credit, minimizing risk and maximizing profitability.Credit scoring has evolved significantly over time, reflecting advancements in data analysis techniques and increasing understanding of financial behavior.
Early methods relied on simple rules and limited data. Modern algorithms leverage vast datasets and complex statistical models to provide more accurate assessments.
Historical Evolution of Credit Scoring
The evolution of credit scoring reflects a progression from simple, rule-based systems to sophisticated statistical models. Early approaches relied on basic criteria like employment history and payment records. As data collection and computational power improved, more complex models emerged. These models incorporated more variables and employed advanced statistical techniques like logistic regression and decision trees. This evolution has significantly improved the accuracy and fairness of credit scoring.
Credit scoring algorithms are used to assess a person’s creditworthiness, which is a big factor in getting loans or credit cards. This directly impacts the availability of contactless payments, as lenders use these scores to determine if someone is a low-risk user for services like Contactless payments. Ultimately, the algorithms help predict future payment behavior, influencing the broader acceptance and adoption of these convenient payment methods.
Types of Credit Scoring Models
Different credit scoring models exist, each with its own methodology and strengths. FICO and VantageScore are two prominent examples, each providing a numerical score reflecting an individual’s creditworthiness. These scores are widely used by lenders to evaluate loan applications and determine credit limits.
Fundamental Principles of Credit Scoring Algorithms
Credit scoring algorithms operate on the principle of assigning numerical scores to individuals based on their financial behavior. These algorithms aim to predict the likelihood of repayment, considering factors like payment history, outstanding debts, and credit utilization. Sophisticated models use statistical techniques to identify patterns and correlations in the data, allowing for more precise risk assessment.
Key Components of Credit Scoring Models
This table Artikels the key components of various credit scoring models, highlighting the scoring range and the weighting of different factors. It’s important to note that the exact weighting factors can vary significantly between models.
| Model | Scoring Range | Weighting Factors |
|---|---|---|
| FICO | 300-850 | Payment history (most significant), amounts owed, length of credit history, new credit, credit mix |
| VantageScore | 300-850 | Payment history, amounts owed, length of credit history, new credit, credit mix, credit utilization |
Data Sources and Input Variables
Credit scoring algorithms rely heavily on various data points to assess an applicant’s creditworthiness. Understanding the different sources and the variables extracted from them is crucial for building accurate and fair models. These models ultimately help lenders make informed decisions about loan applications.Data quality and the accuracy of the input variables directly influence the predictive power and reliability of the credit scoring models.
Inaccurate or incomplete data can lead to misclassifications, resulting in either rejecting legitimate borrowers or approving high-risk ones. Therefore, meticulous data collection and validation procedures are essential to maintain model integrity.
Different Data Sources
Various data sources contribute to the comprehensive assessment of a borrower’s creditworthiness. These sources provide a multifaceted view of an applicant’s financial behavior and history.
- Credit History: This is a fundamental source, encompassing information about past loans, credit card accounts, and other credit products. It reveals the borrower’s repayment history, demonstrating their ability to manage debt responsibly. Examples include the number of accounts opened, the average credit utilization rate, and the presence of any defaults or delinquencies.
- Payment History: This data focuses specifically on the borrower’s track record of paying their debts on time. It reflects their consistency in fulfilling financial obligations. Key indicators include the frequency of late payments, the number of times they missed payments, and the severity of any delinquencies. This is often a critical factor in credit scoring models because it directly indicates the borrower’s reliability.
Credit scoring algorithms are crucial for assessing risk, but they’re increasingly being integrated into other financial services, like embedded finance. This approach allows companies to offer financial products seamlessly within their existing platforms, and it changes how credit scoring algorithms are used and developed. This integration of financial services, a concept often referred to as Embedded finance , is impacting how businesses and consumers access credit.
Ultimately, credit scoring algorithms will need to adapt to this evolving landscape.
- Income: A borrower’s income is a crucial factor, demonstrating their capacity to repay the loan. It includes data on their employment status, salary, and any other sources of income. High income typically signifies a higher capacity to repay the loan, making it a vital input for assessing creditworthiness.
- Other Financial Data: Additional data sources might include bank account statements, investment details, or even public records like tax returns. This can provide a more comprehensive picture of the borrower’s financial situation and overall risk profile.
Key Input Variables
Credit scoring models utilize various input variables derived from the data sources mentioned above. These variables are carefully selected and processed to capture the most relevant information for assessing risk.
- Credit Utilization Ratio: This metric represents the proportion of available credit that a borrower is currently using. A low credit utilization ratio generally indicates responsible credit management and lower risk.
- Number of Credit Accounts: The number of credit accounts held by the borrower can be a proxy for their financial activity and credit history complexity. This can be a factor in assessing risk, though it’s not always a conclusive indicator.
- Length of Credit History: The duration of a borrower’s credit history provides insight into their long-term financial habits and responsible use of credit.
- Payment History (Delinquencies and Defaults): The presence and severity of late payments, missed payments, and defaults are crucial indicators of a borrower’s ability to manage debt.
Importance of Data Quality and Accuracy
The accuracy and completeness of data are paramount in credit scoring. Inaccurate or incomplete data can significantly skew the results and lead to biased or unreliable models.
- Data Validation: Thorough validation procedures should be implemented to identify and correct any errors or inconsistencies in the data. This process helps ensure the quality and reliability of the data.
- Data Cleaning: Data cleaning techniques, such as handling missing values or outliers, are essential to ensure the data is suitable for analysis and modeling. Cleaning ensures data accuracy and consistency.
- Data Transformation: Data transformation techniques can improve the usability and effectiveness of the data for the credit scoring model. This might involve standardization or normalization of variables.
Data Source Comparison
| Data Source | Description | Advantages | Disadvantages |
|---|---|---|---|
| Credit history | Information about past loans, credit cards, etc. | Provides a long-term view of credit behavior | May not reflect current financial situation |
| Payment history | Record of timely payments | Directly indicates repayment ability | May be influenced by external factors |
| Income | Employment status, salary, etc. | Indicates repayment capacity | Can be difficult to verify accurately |
Algorithm Types and Techniques
Credit scoring algorithms use various techniques to assess the likelihood of a borrower repaying a loan. Choosing the right algorithm is crucial, as different algorithms excel in different situations and with varying data characteristics. Understanding their strengths and weaknesses is essential for building accurate and effective credit scoring models.Different algorithms have different approaches to analyzing data and making predictions.
Some algorithms are relatively simple, while others are more complex. The best algorithm for a specific credit scoring model depends on the available data, the desired level of accuracy, and the computational resources available.
Linear Regression
Linear regression models the relationship between a dependent variable (e.g., loan default probability) and one or more independent variables (e.g., credit history, income). It assumes a linear relationship between the variables. This simplicity makes linear regression computationally efficient and easy to interpret.Advantages of linear regression include its straightforward interpretation, efficiency, and ease of implementation. It can be helpful when dealing with large datasets and when the relationship between variables is reasonably linear.
Credit scoring algorithms are crucial for assessing risk in lending. Neobanks, like many online-only financial institutions, heavily rely on these algorithms to make quick and efficient lending decisions. These algorithms help determine the trustworthiness of customers and manage risk, which is essential for the growth of neobanks ( Neobanks ) and other financial services. Ultimately, strong credit scoring algorithms are vital for the success of any financial institution.
For example, a linear regression model could predict the probability of default based on a borrower’s credit score and income.Disadvantages include its inability to capture non-linear relationships between variables. If the relationship between the variables is non-linear, the model may not accurately predict the default probability. Also, it struggles with handling non-numeric data or missing values.
Logistic Regression
Logistic regression is used when the dependent variable is categorical (e.g., default or no default). It models the probability of an event occurring using a logistic function. This function outputs a probability between 0 and 1.Advantages include its ability to handle categorical variables, its ability to produce probabilities, and its interpretability. A logistic regression model can predict the probability of a borrower defaulting on a loan based on various factors.
For example, a logistic regression model could predict the probability of a borrower defaulting based on credit score, payment history, and income.Disadvantages include the assumption of linearity in the log-odds and difficulty in handling high dimensionality. If the relationship between the predictors and the outcome is non-linear, the model’s accuracy might suffer. It can also be sensitive to outliers.
Decision Trees
Decision trees use a tree-like structure to model decisions and their possible consequences. Each node represents a decision based on a variable, and each branch represents an outcome. This approach is intuitive and easy to understand.Advantages of decision trees include their interpretability, ability to handle both numerical and categorical data, and robustness to outliers. Decision trees can be visualized easily, making it easier to understand how the model makes decisions.
For example, a decision tree model could determine if a borrower should be approved for a loan based on their credit score, debt-to-income ratio, and employment history.Disadvantages of decision trees include the tendency to overfit to the training data, leading to poor performance on unseen data. They can also be unstable, meaning small changes in the data can lead to significant changes in the tree structure.
Handling Missing Data
Missing data is a common issue in credit scoring. Various techniques can be used to address missing values. These techniques include imputation methods, where missing values are replaced with estimated values, and methods that consider the missing data patterns during model training.Different algorithms handle missing data in different ways. Linear regression, for example, might not perform well if the data is missing at random.
Logistic regression and decision trees have different approaches to missing values. Logistic regression often requires careful handling of missing data using imputation techniques. Decision trees are more robust, but still need to address missing data issues, potentially through removal or imputation.
| Algorithm Type | Strengths | Weaknesses |
|---|---|---|
| Linear Regression | Simple, interpretable, computationally efficient | Assumes linearity, struggles with non-numeric data, sensitive to outliers |
| Logistic Regression | Handles categorical variables, produces probabilities, interpretable | Assumes linearity in log-odds, sensitive to outliers, can be affected by high dimensionality |
| Decision Trees | Interpretable, handles numerical and categorical data, robust to outliers | Prone to overfitting, unstable, can be computationally expensive for large datasets |
Model Validation and Evaluation
Validating and evaluating credit scoring models is crucial for ensuring their accuracy, fairness, and reliability. A well-validated model can effectively predict creditworthiness, minimize risk, and ultimately contribute to sound lending practices. Proper evaluation helps identify potential weaknesses in the model and areas for improvement, leading to a more robust and trustworthy system.Model validation and evaluation involves a systematic process of assessing the model’s performance on unseen data, identifying potential biases, and calibrating the model’s output to ensure accurate risk assessment.
This process ensures the model’s ability to generalize well to new data and accurately predict the likelihood of default for future borrowers.
Model Validation Methods
Model validation involves using various methods to assess the model’s ability to generalize to new, unseen data. This is crucial to prevent overfitting, where the model performs exceptionally well on the training data but poorly on new data. Common methods include:
- Holdout Method: A portion of the dataset is set aside as a test set, which the model never sees during training. This allows for an unbiased assessment of the model’s performance on data it hasn’t encountered before. For example, 20% of the data could be reserved as a test set.
- Cross-Validation: This method involves dividing the dataset into multiple subsets (folds). The model is trained on a combination of these folds and tested on the remaining fold. This process repeats until each fold has served as the test set. This provides a more robust estimate of the model’s performance by evaluating it on different subsets of the data.
- Bootstrap Validation: Repeatedly sampling the dataset with replacement to create multiple training sets. The model is trained on each bootstrap sample, and its performance is averaged across the samples. This is particularly useful when the dataset is relatively small.
Model Performance Metrics
Evaluating model performance requires using appropriate metrics. These metrics quantify the model’s ability to correctly classify borrowers as high-risk or low-risk. Several key metrics are commonly used:
- Accuracy: The proportion of correctly classified instances. A high accuracy suggests the model correctly identifies the majority of cases. For example, if a model predicts 95 out of 100 cases correctly, the accuracy is 95%. However, accuracy can be misleading if the classes are imbalanced.
- Precision: The proportion of correctly predicted positive instances out of all instances predicted as positive. It measures the accuracy of positive predictions. For example, if a model predicts 80 out of 100 borrowers as high-risk, and 60 of them are actually high-risk, the precision is 60/80 = 75%.
- Recall: The proportion of correctly predicted positive instances out of all actual positive instances. It measures the model’s ability to identify all relevant cases. For example, if there are 80 high-risk borrowers in the dataset, and the model correctly identifies 60 of them, the recall is 60/80 = 75%.
- F1-Score: The harmonic mean of precision and recall, providing a balanced measure of the model’s performance. It is particularly useful when precision and recall are equally important. A higher F1-score generally indicates better performance.
- AUC (Area Under the ROC Curve): A measure of the model’s ability to distinguish between classes. An AUC of 1 indicates perfect classification, while an AUC of 0.5 indicates random classification.
Model Calibration
Model calibration ensures that the model’s predicted probabilities accurately reflect the actual risk of default. For example, if the model predicts a 70% probability of default for a borrower, it should indeed be more likely to default than a borrower with a 30% probability.
Bias Identification and Mitigation
Bias in credit scoring models can lead to unfair or discriminatory outcomes. Techniques to identify and mitigate bias include:
- Data Analysis: Examining the data for patterns and distributions across different demographic groups to detect potential biases.
- Model Auditing: Evaluating the model’s predictions for different demographic groups to determine if disparities exist.
- Feature Engineering: Adjusting or removing features that may correlate with protected characteristics, reducing their impact on the model’s output.
Model Evaluation Metrics Summary
| Metric | Description | Interpretation |
|---|---|---|
| Accuracy | Proportion of correctly classified instances. | Higher is better, but can be misleading with imbalanced classes. |
| Precision | Proportion of correctly predicted positives out of all predicted positives. | Higher is better, emphasizes minimizing false positives. |
| Recall | Proportion of correctly predicted positives out of all actual positives. | Higher is better, emphasizes minimizing false negatives. |
Ethical Considerations and Bias Mitigation
Source: slideteam.net
Credit scoring algorithms, while powerful tools for assessing creditworthiness, can perpetuate existing societal biases. Understanding and mitigating these biases is crucial for ensuring fairness and responsible lending practices. Fair and transparent credit scoring models build trust and contribute to a more equitable financial system.The use of credit scoring algorithms in lending decisions can disproportionately affect certain demographic groups.
These algorithms can reflect and amplify existing societal biases, leading to unfair outcomes for borrowers. This is a significant ethical concern, as it can result in unequal access to credit, hindering economic opportunities for marginalized communities. Mitigating these biases is essential to promote fairness and inclusivity in the financial system.
Potential Biases in Credit Scoring Models
Credit scoring models can incorporate variables that inadvertently reflect historical societal biases. These variables might include factors related to race, ethnicity, gender, or geographic location, even if these factors are not directly related to creditworthiness. For example, if a model heavily weights credit history from a particular neighborhood with a higher historical default rate, it might unfairly penalize borrowers from that neighborhood, even if their individual credit behavior is similar to those in other neighborhoods.
Furthermore, data sets used for training credit scoring models might be incomplete or skewed, potentially leading to biased results.
Credit scoring algorithms are pretty important for assessing risk, but they’re only part of the picture. Modern point-of-sale (POS) systems Point-of-sale (POS) systems are increasingly incorporating data from transactions, like purchase frequency and amounts, to further refine credit scoring models. This real-time data stream can significantly improve the accuracy and efficiency of credit scoring algorithms.
Methods for Mitigating Bias in Credit Scoring Models
Various techniques can be employed to reduce bias in credit scoring models. These include careful data selection and preprocessing to remove or adjust for potentially biased variables. Model developers should also consider using alternative variables that are less prone to bias, such as income or employment stability, rather than ones that could reflect past discrimination. Regularly evaluating and testing the model for bias using diverse datasets is critical.
Importance of Fairness and Transparency in Credit Scoring
Fairness and transparency are essential in credit scoring. Fairness ensures that credit decisions are not influenced by discriminatory factors and that all borrowers have an equal opportunity to access credit. Transparency allows borrowers to understand how their creditworthiness is assessed, enabling them to identify and address potential issues. Transparency also facilitates greater trust in the credit scoring system.
Guidelines for Developing Ethical and Unbiased Credit Scoring Models
Developing ethical and unbiased credit scoring models requires adherence to several guidelines. These guidelines include:
- Using diverse and representative datasets for model training to avoid over-representing certain groups.
- Identifying and removing potentially biased variables from the dataset, or adjusting their weight in the model.
- Implementing fairness constraints within the model development process, ensuring that the model treats all applicants fairly.
- Regularly testing and validating the model for bias and fairness across different demographic groups.
- Documenting the model’s variables, methodology, and any identified biases, ensuring transparency and accountability.
Regulatory Landscape Surrounding Credit Scoring
Regulations are increasingly focusing on the ethical use of credit scoring algorithms. Governments and regulatory bodies are implementing guidelines and frameworks to ensure that credit scoring models are fair, transparent, and unbiased. These regulations often require credit scoring models to be regularly audited and tested for potential bias. Examples include the Fair Credit Reporting Act (FCRA) in the US, and similar legislation in other jurisdictions.
These regulations aim to prevent discrimination and promote fairness in lending practices. Compliance with these regulations is essential to maintain the credibility and trustworthiness of credit scoring systems.
Applications and Future Trends: Credit Scoring Algorithms
Credit scoring algorithms are increasingly vital in a wide range of sectors, enabling more informed and efficient decision-making. From lending institutions to insurance companies, these algorithms are crucial for evaluating risk and determining appropriate pricing and terms. This section delves into the diverse applications of credit scoring, explores emerging trends, and examines the pivotal role of AI and machine learning in shaping the future of credit scoring.Beyond traditional lending, credit scoring algorithms are proving useful in a range of contexts.
Understanding how these algorithms are used in various fields and anticipating future developments is essential for grasping their impact on the financial landscape.
Applications of Credit Scoring
Credit scoring algorithms are not confined to the realm of personal loans. They are widely applied across diverse sectors, playing a key role in various financial and non-financial decisions. Examples include:
- Insurance: Insurers use credit scores to assess risk and set premiums for policies, particularly for auto, homeowners, and life insurance. A lower credit score often correlates with a higher perceived risk, leading to increased premiums.
- Lending: This is the most common application, used by banks, credit unions, and online lenders to evaluate loan applications and determine interest rates and loan terms.
- Telecommunications: Companies like mobile providers leverage credit scores to evaluate potential subscribers and set credit limits for services like data packages or phone lines.
- Retail: Retailers may use credit scores to assess the creditworthiness of customers for store credit cards or extended payment plans.
- Employment: In some cases, credit scores may be considered as part of a larger risk assessment for employment purposes. This is controversial and often met with regulatory scrutiny.
Emerging Trends and Future Directions
The field of credit scoring is continuously evolving, driven by advancements in technology and changing market needs. Key trends include:
- AI and Machine Learning Integration: AI and machine learning algorithms are becoming increasingly sophisticated, enabling the development of more accurate and personalized credit scoring models. These models can analyze vast amounts of data, including non-traditional data sources, to create more comprehensive risk assessments.
- Expansion of Data Sources: Beyond traditional credit reports, credit scoring models are incorporating alternative data sources, such as social media activity, online purchase history, and even mobile phone usage patterns. This broadening of data sources provides a more holistic view of a borrower’s financial behavior and risk profile.
- Algorithmic Advancements: Continuous improvement in algorithms results in more robust and accurate risk assessments. This leads to more precise credit risk evaluations, reducing errors and improving overall decision-making.
The Role of AI and Machine Learning
AI and machine learning are revolutionizing credit scoring by enabling more sophisticated models that can analyze vast datasets. These models can identify complex patterns and relationships that traditional methods might miss. Furthermore, AI-powered systems can adapt to changing economic conditions and market dynamics, leading to more dynamic and responsive credit scoring models.
Challenges and Opportunities
While AI and machine learning offer significant opportunities, there are challenges to consider. Ensuring fairness, transparency, and avoiding bias in credit scoring models is critical. Also, regulatory compliance and data privacy are paramount.
Examples in Different Sectors
The application of credit scoring extends beyond financial institutions. For instance, telecommunications companies use credit scoring to assess subscriber risk, and retailers use it for extended payment plans.
Credit scoring algorithms are used to assess risk, and that’s a key factor in many investment decisions. They’re often used to determine eligibility for fractional investing opportunities, which allow you to invest in assets like real estate or private equity with smaller amounts of capital. These algorithms are crucial for assessing risk and ensuring fair returns for investors, in the context of fractional investing.
Understanding the algorithms used is important to make informed decisions in the market.
Future of Credit Scoring: A Table
| Aspect | Description |
|---|---|
| AI integration | Sophisticated AI/ML models will be used for more precise risk assessment and personalized credit scores, potentially incorporating non-traditional data. |
| Data sources | A wider range of data sources, including alternative data and behavioral data, will be incorporated to create a more comprehensive risk profile. |
| Algorithmic advancements | Algorithms will become more complex and sophisticated, improving accuracy and mitigating biases. This includes greater emphasis on explainable AI (XAI) models. |
Outcome Summary
In conclusion, credit scoring algorithms are complex systems with a profound impact on financial access. While they offer valuable tools for risk assessment, it’s essential to acknowledge their potential for bias and work towards more equitable and transparent models. Future developments in AI and machine learning promise to further refine these algorithms, but the ethical considerations surrounding their application remain paramount.
Common Queries
How accurate are credit scoring algorithms?
The accuracy of credit scoring algorithms varies depending on the model and the quality of the data used. While they are generally quite effective, there’s always a margin for error. This is why it’s important to understand the limitations of these algorithms and to seek clarification when needed.
What are the different types of data used in credit scoring?
Credit scoring models use a range of data, including credit history, payment history, income, and even public records. The specific data points and their weightings vary significantly between different models.
How can I improve my credit score?
Improving your credit score often involves consistently making timely payments, keeping your credit utilization low, and avoiding opening too many new credit accounts at once. Managing your credit responsibly is key to building a strong credit profile.